Pour mon projet cutevariant, j'ai été amené à devoir convertir l'ontologie HPO (disponible au format obo) en base de données SQLite. Pour ceux qui ne connaissent pas, HPO (Human Phenotype Ontology) est une ontologie décrivant des signes cliniques. C'est-à-dire un vocabulaire standardisé et hiérarchisé afin d'aider les ordinateurs à comprendre le charabia des médecins. Si je vous donne par exemple le mot céphalée (maux de tête) il y a un terme anglais Headache associé à l'identifiant HPO:0002315. Ce terme est enfant du terme Abnormality of nervous system physiology, lui même enfant de Abnormality of the nervous system, lui même enfant de Organ abnormality qui est la racine de l'ontologie. Jeter un oeil sur phenomizer pour explorer cette ontologie.
Afin de réaliser cette transformation (en l'occurrence un fichier hpo.obo en fichier hpo.sqlite), je me suis vu écrire plein de ligne de code et faire du parsing dans tous les sens. Lorsque j'ai réussi à réaliser cette transformation en 10 lignes à peine à l'aide de networkx, c'est à ce moment que j'ai eu la révélation.... Les graphes c'est vraiment GÉNIAL !!!!!!!!
Imbrication d'ensemble
Les données dans HPO ressemblent à un arbre. Je me suis alors rappelé d'une méthode pour représenter des données hiérarchisées dans une base de données relationnelle qu'on appelle l'imbrication d'ensemble.
Naïvement, pour sauvegarder un arbre dans une base de donnée SQL on ferait un truc simple de ce genre:
Table Node
- id (primary key)
- name (string)
- parent (foreign key)
Mais dans ce cas, certaines requêtes peuvent être complexes. Par exemple si vous demandez tous les enfants d'un noeud particulier, cela nécessitera d'écrire une requête récursive gourmande.
La méthode d'imbrication consiste à associer à chaque noeud des bornes droites et gauches correspondant aux indices d'un parcours d'arbre en profondeur.
Table Node
- id (primary key)
- name (string)
- left (integer)
- right (integer)
Par exemple dans l'arbre suivant, on part de la borne gauche (1) de la racine Food et on descend l'arbre jusqu'aux feuilles et ainsi de suite, jusqu'à revenir sur la borne droite (18) de la racine.
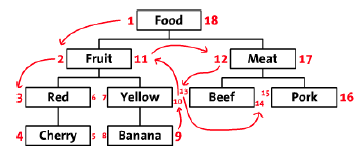
Grâce à ça, en une seul requête il est facile d'obtenir tous les enfants d'un noeud. Par exemple pour sélectionner tous les enfants de fruit, il suffit de sélectionner tous les noeuds avec une borne gauche > 2 et une borne droite < 11. Facile non ?
SELECT name FROM node WHERE left > 2 AND right < 11
Convertion d'un DAG en arbre
Le problème c'est que l'ontologie HPO n'est pas un arbre. C'est un graphe orienté acyclique (DAG). C'est-à-dire que certains noeuds peuvent avoir plusieurs parents. Par chance, la lib networkx en python permet de convertir un DAG en arbre en dupliquant les noeuds qui pose problème.
Prenons un graphe simple avec le noeud D ayant deux parents B et C.
import networkx as nx
g = nx.DiGraph()
g.add_nodes_from(["A","B","C","D"])
g.add_edge("A","B")
g.add_edge("A","C")
g.add_edge("B","D")
g.add_edge("C","D")
nx.draw_networkx(g)
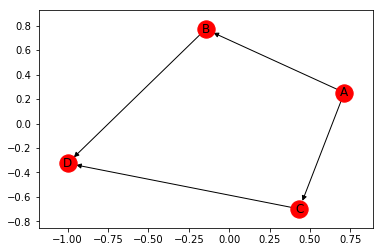
On peut alors transformer ce DAG en arbre avec :
tree = nx.dag_to_branching(g)
nx.draw_networkx(tree)
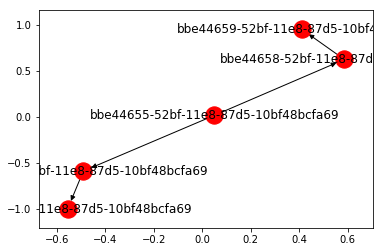
Tous les noeuds ont été renommés avec un identifiant unique et le noeud D a été dupliqué.
Pour savoir à quels noeuds ces identifiants correspondent :
for node in tree.nodes(data="source"):
print(node)
('3b62eb6b-52c0-11e8-87d5-10bf48bcfa69', 'A')
('3b62eb6c-52c0-11e8-87d5-10bf48bcfa69', 'B')
('3b62eb6d-52c0-11e8-87d5-10bf48bcfa69', 'D')
('3b62eb6e-52c0-11e8-87d5-10bf48bcfa69', 'C')
('3b62eb6f-52c0-11e8-87d5-10bf48bcfa69', 'D')
Parcours de l'arbre en profondeur
Pour sauvegarder cet arbre dans une base de donnée SQL, il faut dans un premier temps parcourir l'arbre en profondeur, et associer à chaque noeud les bornes gauche et droite. Pour cela, rien de plus simple avec les algorithmes de parcours en profondeur de networkx (dfs):
index = 0
for i in nx.dfs_labeled_edges(tree):
node_name_1 = i[0]
node_name_2 = i[1]
sens = i[2]
if sens == "forward":
tree.node[node_name_2].update({"left": index})
if sens == "reverse":
tree.node[node_name_2].update({"right": index})
index+=1
Au final, il suffit de reparcourir l'arbre et faire des INSERT SQL pour chaque noeud.
Étant donné qu'il y a des noeuds dupliqués, il est plus intéressant de créer 2 tables. L'une contenant les noeuds réels (Nodes) et l'autre contenant les noeuds dupliqués (Trees). On peut également rajouter comme information la profondeur du noeud dans l'arbre ainsi que son noeud parent.
Table Nodes
- id (primary key)
- name (string)
Table Trees
- id (primary key)
- node_id (foreign key)
- left (int)
- right (int)
- depth (int)
- parent_id (foreign_key)
Hpo2Sqlite sur github
Le code source pour convertir hpo.obo en hpo.sqlite, ainsi que la base de données sqlite sont dispo à ces adresses:
Cette méthode est compatible avec l'ontologie HPO parce que toutes les relations sont de type "is_a". Donc en théorie, pour n'importe quelle autre ontologie du même type, cet algorithme peut fonctionner.
PS: Merci à mes profs Olivier Dameron (ontologie) et Emmanuelle Becker (Graphe) de m'avoir appris toutes ces notions!
Ce site est versionné sur GitHub. Vous pouvez corriger des erreurs en vous rendant à cette adresse
Go Top
comments powered by Disqus