Pouvez vous me citer toutes les personnes ayant eu un Oscar et le prix Nobel ? Quelles sont les lieux de naissance de toutes les célébrités se prénommant Antoine ? Trouvez moi tous les médicaments qui cible des gènes liés à la prolifération cellulaire ?
Ce genre de question peut être difficile à répondre si vous utiliser seulement un moteur de recherche comme Google. Mais en utilisant une ontologie et un langage dédié appelé SPARQL
, vous allez pouvoir répondre à toutes ces questions en un éclair.
Dans ce billet, je vous propose d'explorer l'ontologie de Wikipedia (wikidata) et utiliser SPARQL pour construire une carte du monde montrant le nombre de groupe de rock par habitant de chaque pays.
Qu'est ce qu'une ontologie ?
Une ontologie est une façon d'organiser le savoir en reliant de nombreux concepts entre eux. Plus exactement, c'est un graphe construit à partir d'un ensemble de triplets composé chacun d'un sujet, d'un prédicat et d'un objet.
Par exemple, les 3 triplets suivant permettent de relier les Rolling Stones au Fish and Chips.
# SUJET PREDICAT OBJET
<The Rolling Stones> <est d'origine du> <Royaume uni>
<The Rolling Stones> <est un groupe de> <Rock>
<Le Fish and Chips> <est d'origine du> <Royaume uni>
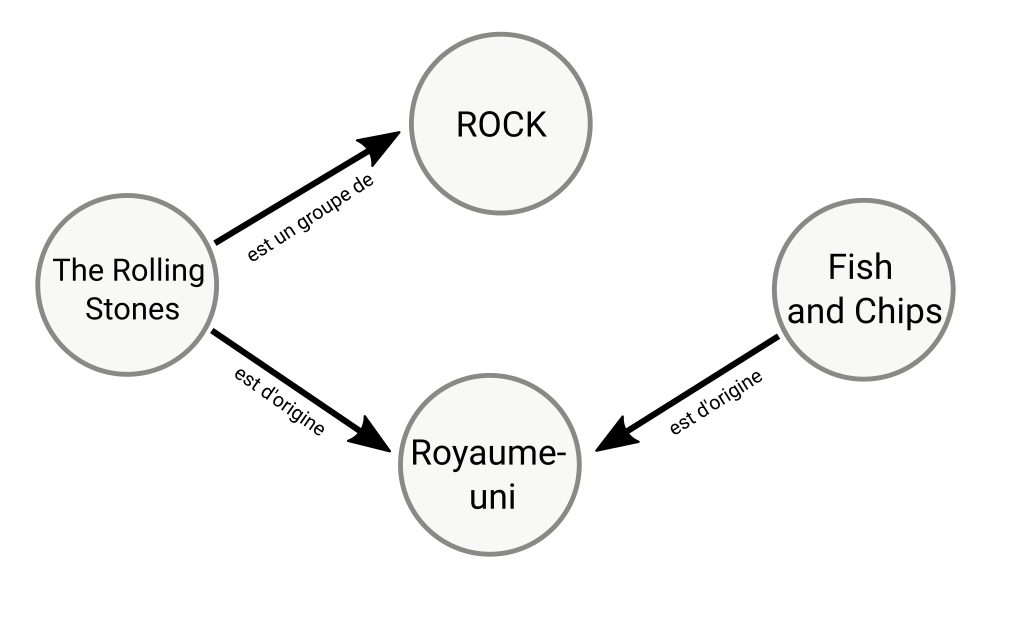
Exemple d'ontologie
Dans une ontologie, les concepts sont définis par un identifiant unique.
Sur wikidata, Le concept "Rolling Stones" porte l'identifiant Q11036 et le concept "Fish and Chips" porte l'identifiant Q203925. Il en est de même pour les prédicats et les objets. Ainsi, les triplets précédents peuvent s'écrire de la manière suivante:
wd:Q11036 wdt:P17 wd:Q145
wd:Q11036 wdt:P31 wd:Q5741069
wd:Q203925 wdt:P17 wd:Q145
Tous les triplets d'une ontologie sont généralement stockés dans un fichier texte au format RDF ou dans une base de donnée dédiée appelée triple store. Vous trouverez sur internet de nombreuses ontologies, notamment en biologie avec par exemple GO ( Gene ontology ) décrivant les éléments cellulaires ou HPO (Human Phenotype Ontology) décrivant les signes cliniques des maladies. L'ensemble des ontologies disponible sur le web vise à former ce qu'on appelle le web sémantique.
Le langage SPARQL
SPARQL est un langage dédié à l'extraction d'information depuis une ontologie. Je vous invite à exécuter les requêtes suivantes avec l'outil en ligne mis à disposition par wikidata.
Le principe est assez simple. Il faut écrire des triplets en remplaçant les concepts inconnus qui nous intéressent par des variables.
Par exemple pour trouver tous les groupes de rocks anglais, nous cherchons ?x tel que:
- ?x est d'origine anglaise
- ?x est un groupe de rock
En SPARQL, cela donne :
SELECT ?x
WHERE {
?x wdt:P17 wd:Q145.
?x wdt:P31 wd:Q5741069.
}
Pour avoir le noms des concepts en français:
SELECT ?x ?xLabel
WHERE
{
?x wdt:P17 wd:Q145.
?x wdt:P31 wd:Q5741069.
SERVICE wikibase:label { bd:serviceParam wikibase:language "[AUTO_LANGUAGE],en". }
}
Et pour récupérer tous les groupes de rocks, le pays d'origine et le nombre d'habitant, je fais :
SELECT ?groupeLabel ?paysLabel ?population
WHERE
{
?groupe wdt:P31 wd:Q5741069;
wdt:P495 ?pays.
?pays wdt:P1082 ?population.
SERVICE wikibase:label { bd:serviceParam wikibase:language "[AUTO_LANGUAGE],en". }
}"""
Je vous invite à lire ce tutoriel pour plus de précision et à bien utiliser l'autocompletion de l'éditeur (ctrl+espace) pour éviter à devoir chercher les concepts un par un.
Exécution depuis Python
L’éditeur SPARQL de wikidata propose un bouton magique pour générer du code dans différents langages.
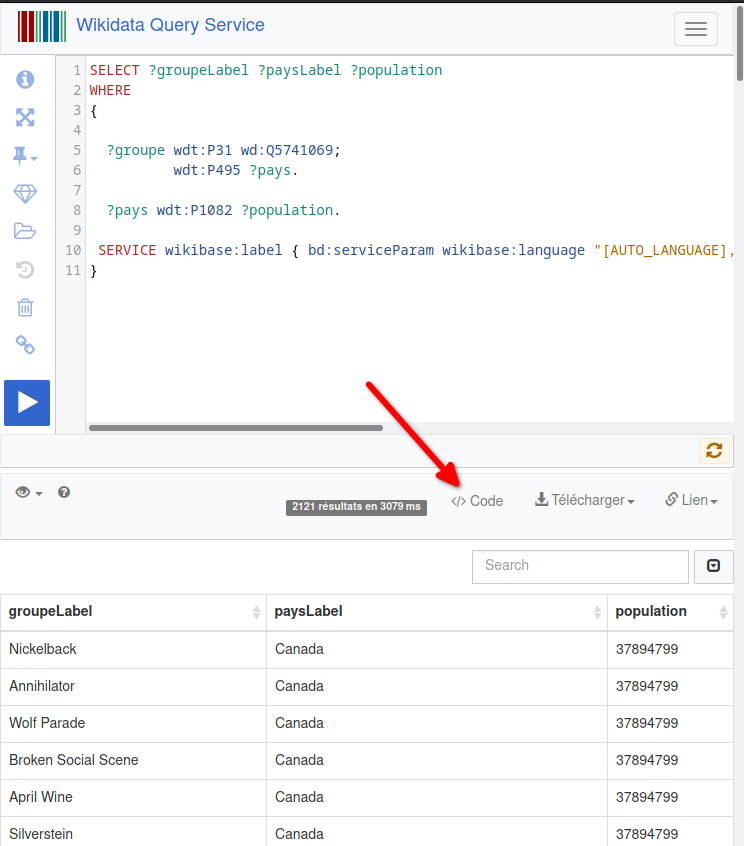
Editeur SPARQL de wikidata
Ainsi vous pouvez exécuter en python une requête SPARQL, récupérer le résultat en JSON et construire un Dataframe avec pandas. Vous aurez besoin du package sparqlwrapper.
# Installer sparqlwrapper
#!pip install sparqlwrapper
import sys
from SPARQLWrapper import SPARQLWrapper, JSON
import pandas as pd
endpoint_url = "https://query.wikidata.org/sparql"
query = """
SELECT ?groupeLabel ?paysLabel ?population
WHERE
{
?groupe wdt:P31 wd:Q5741069;
wdt:P495 ?pays.
?pays wdt:P1082 ?population.
SERVICE wikibase:label { bd:serviceParam wikibase:language "[AUTO_LANGUAGE],en". } # Helps get the label in your language, if not, then en language
}"""
def get_results(endpoint_url, query):
user_agent = "WDQS-example Python/%s.%s" % (sys.version_info[0], sys.version_info[1])
# TODO adjust user agent; see https://w.wiki/CX6
sparql = SPARQLWrapper(endpoint_url, agent=user_agent)
sparql.setQuery(query)
sparql.setReturnFormat(JSON)
return sparql.query().convert()
results = get_results(endpoint_url, query)
# construction d'un dataframe
df = pd.io.json.json_normalize(results['results']['bindings'])
df = df[["groupeLabel.value","paysLabel.value", "population.value"]]
df.columns = ["groupe","pays","population"]
La carte !
J'ai juste mouliné le tout avec geopandas sur un notebook jupyter disponible ici, et le tour est joué.
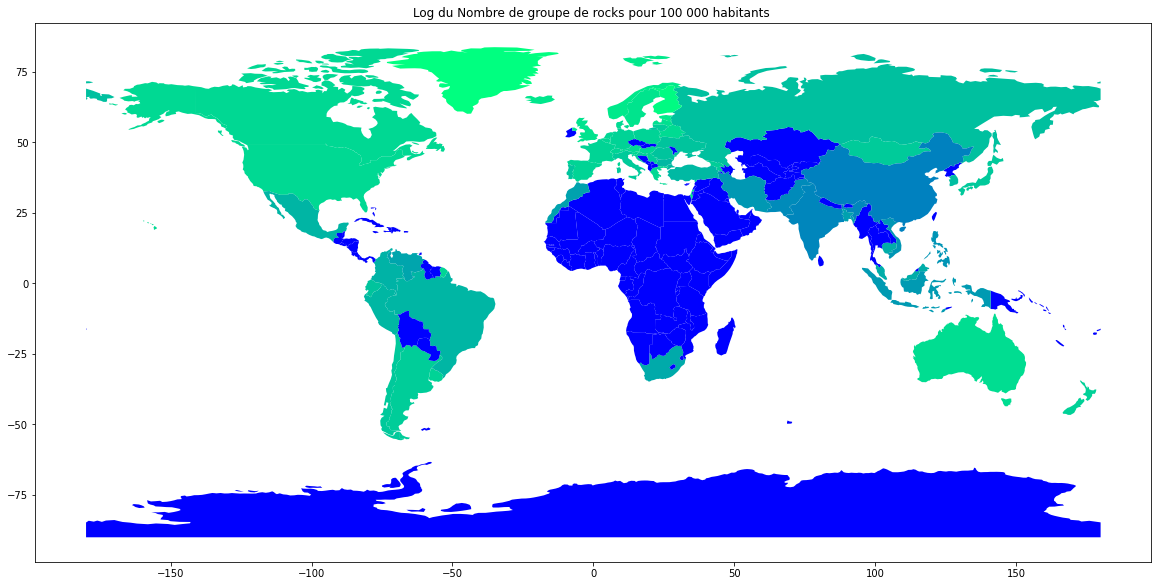
Nombre de groupes de rock par pays
Les pays ayant le plus de groupes de rocks par habitant, sont les pays nordiques ( Finlande, Norvège, Groenland, Islande, Suède). 1 groupe référencé en Iran, 86 groupes pour la France et 270 pour le Royaume-unis !
Note
Toutes les questions dans l'introduction sont disponible dans le menu exemple de l’éditeur SPARQL de wikidata.
Référence
Ce site est versionné sur GitHub. Vous pouvez corriger des erreurs en vous rendant à cette adresse
Go Top
comments powered by Disqus