Au temps ou le téléphone portable était un objet de luxe et de démesure, la seule façon d'envoyer un message pendant un cours de philosophie, était d'utiliser un petit bout de papier que l'on faisait passer d'élève à élève. Il fallait écrire en petit pour maximiser la quantité d'information transmis lors d'un envoi. De plus, pour éviter toute interception du message par le professeur certains avaient recours à des cryptages plus ou moins efficaces. A cette époque, ou je programmais sur calculette Ti-82 pendant mes cours de philo, j'aurais aimé connaître l'algorithme de la transformation de Burrows-Wheeler. J'aurai pu économiser encre et papier en compressant l'information de mes messages, mais surtout je me serais éclaté à coder un encodeur/décodeur de petits mots sur ma calculette.
En effet, cette algorithme est utilisé dans 2 cas particuliers. La compression que nous allons aborder dans cette article, mais aussi l'indexation utilisée dans la recherche de motif textuel. Ce dernier point fera l'objet d'un prochain article.
Compression du texte
Une technique de compression appelée codage par plages, souvent utilisée dans la compression d'image, consiste à remplacer des répétitions par le nombre d'occurrence de cette répétition. Par exemple, on peut remplacer la suite de pixel suivant :
jaune-jaune-jaune-jaune-jaune-rouge
par :
5jaune - rouge
On peut appliquer cette méthode sur une chaîne de caractère. C'est à dire en remplaçant les répétitions de lettres consécutives par leurs nombres d’occurrences. Par exemple, avec le mot "anticonstitutionnellement" On obtient :
anticonstitutio2ne2lement
Pas très efficace n'est ce pas ? En effet, remplacer 2 lettres par 1 chiffre + 1 lettre, ne diminue pas la longueur du message. il faudrait des répétitions de 3 lettres au minimum pour être compressible, et c'est rarement le cas dans un texte. C'est ici qu'intervient l'algorithme de Burrows-Wheeler. Il s'agit d'une transformation réversible d'une chaîne de caractère vers une autre ayant la propriété d'avoir des lettres identiques contiguës. Il est alors possible de compresser cette chaîne plus efficacement.
Transformation de Burrows-Wheeler
Dans ce qui suit, nous allons faire la transformation de Burrows-Wheeler en utilisant le mot "banane".
Tout d'abord, rajoutons le caractère "$" à la fin du mot: banane$. Lorsque l'on range des lettres dans l'ordre lexicographique, le "$" se situe avant la lettre "A", de la même façon que le "B" se trouve avant le "C". Ce caractère nous servira de repère par la suite.
Puis, nous allons créer la matrice suivante en décalant chaque ligne d'une lettre, en faisant une sorte de rotation (Figure ci dessous). La matrice obtenue est de taille L x L ou L est la longueur du mot.

Une fois la matrice construite, nous ordonnons les lignes dans l'ordre lexicographique. Les lignes commençant par un "A" sont en haut, et ainsi de suite. Nous obtenous alors la matrice ci-dessous. La transformation de Burrows-Wheeler correspond à la dernière colonne. C'est aussi simple que ça.

La transformation du mot "banane", donne "ebn$naa". Et comme vous pouvez le constater, certaines lettres identiques sont réunies.
Bon, c'est pas très impressionnant avec le mot banane. Mais avec le mot anticonstitutionnellement, on obtient : t$inlmtttleenooeaicnnnusit. Et cette fois, on observe des répétitions de plus de 2 lettres, qui nous permet de compresser le mot de cette façon :
t$inlm3tl2en2oeaic3nusit #24 lettres
anticonstitutio2ne2lement #25 lettres
Toujours pas impressionné ? Essayons cette fois avec un extrait de l'origine des espèces :
Texte original ( 1102 lettres )
Let it also be borne in mind how infinitely complex and close-fitting are the mutual relations of all organic beings to each other and to their physical conditions of life; and consequently what infinitely varied diversities of structure might be of use to each being under changing conditions of life. Can it, then, be thought improbable, seeing that variations useful to man have undoubtedly occurred, that other variations useful in some way to each being in the great and complex battle of life, should occur in the course of many successive generations? If such do occur, can we doubt (remembering that many more individuals are born than can possibly survive) that individuals having any advantage, however slight, over others, would have the best chance of surviving and of procreating their kind? On the other hand, we may feel sure that any variation in the least degree injurious would be rigidly destroyed. This preservation of favourable individual differences and variations, and the destruction of those which are injurious, I have called Natural Selection, or the Survival of the Fittest
Compression ( 893 lettres )
2t.e,?d?le.yftxt;g,rsgtshgxotd,2hc4en,trdydgldetyeldhe3ofy2erIdnsd,telrgn2etwt2etnre3fotf2enyedoysne2sedselne,lhetr,rnsfle2,rnfyflyfne)g,gfrend2nengo,feyesldgef2syrtdyen,yes, e2snrent2edtds2edesd4 $5 rb3e trcuvu c2u hmC2ch7 2hgv 2m4 5v2e6heivl3irbN4hfmwo8 m 2ai2 2u2i3 u3o2nci2aua9 oueu3cel3nelnl4nenen n3 2n 3nie2 n3ia3hrbv2hwvhnlrerhwrhlscbhbrvrbsvmsvglfs2f3 l2r2lirytrsf2sdbe2b2herS2tmrhrgushdh2vhnfbhvscirctb2dLw2l8oI4o 3i fi2n-2e9nra iu2in en5ctc c2tw3t4 16twT2ts2 3gp4rsnshg3vrt3ldmlr6 mk5 2vtgeret2e2f2 11t2r2eh2 2ns2dFfvsv4dv2n 3aualaeue3ubtb el2p3 s2ac3ae2dbet4 eoe3 2oi 2aoai2oair3iOaeoae3ai5aiu2o3iure11iaia4i8oae4as4tdtr3 r12 s2c4i2c7ic m 2bhlp4 2dh2whvc2i 2hr 2m2 m 4euieieoe3ueaoa2uagcrg (epo5a e2u2o2ptueue2te3ue2l3neig2n2unrnru2o 2une syrs l o3ea2e6 sbi2ah2sh2ae3ahinb2it18 4o2 it3a2ca2i4atn5 3s2iauacdt2d2o2s2rqo2f3o2 2co2ts2jcoS2s2o3 mid5 rai2aioe5ia3rao3 o4 2en2lanlnlan2loh
Suffixe Array
Si vous avez compris comment réaliser une Burrow-Wheeler, attendez avant de vous jeter sur l’implémentation du code et la création d'une matrice...
Avez-vous pensé à la mémoire? Un texte de 100 000 mot, nécessite de construire une matrice de L x L, soit 100 000 * 100 000 = 10^10 bytes ! Ça fait beaucoup pour pas grand chose.
Heureusement une autre méthode basée sur les suffix array permet d'économiser votre temps et votre mémoire pour réaliser cette transformation.
La suffix array, d'un mot, est l'ensemble des suffixes de ce mot.
Par exemple, le mot banane$ , possède les suffixes suivant avec leurs rangs correspondants :

Si nous ordonnons cette liste de suffixe dans l'ordre lexicographique, et que nous la comparons avec la matrice précédente, vous pouvez trouver une relation en faisant marcher vos méninges.

En effet, on observe que la nième lettre de la transformation de Burrow-Wheeler correspond dans le mot banane, au rang du suffix soustrait de 1... Rien compris? C'est normal. Lisez la suite, pour comprendre.
Regardez le 6ème suffixe, "nanes$" , il est de rang 2. Puis chercher dans le mot banane$ en bas, la lettre à l'index 2-1, soit l'index 1 . Il s'agit de la lettre "A" qui correspond bien à la 6ème lettre de la transformation de Burrow-Wheeler.
Si vous avez pigé, il n'y a plus besoin de créer de matrice. La dernière colonne peut directement être obtenu en utilisant le suffix arrays. Vous avez juste besoin de créer une fonction qui retourne les rangs des suffixes après les avoir ordonnés lexicographiquement.
Parfois un algorithme vaut mieux qu'une explication :
def suffixArray(s):
''' creation du suffixe array avec leurs rangs ordonnés '''
satups = sorted([(s[i:], i) for i in range(0, len(s)+1)])
return map(lambda x: x[1], satups)
def bwt(t):
''' transformation de Burrow-wheeler '''
bw = []
for si in suffixArray(t):
if si == 0:
bw.append('$')
else:
bw.append(t[si-1])
return ''.join(bw)
Inverser la transformation
C'est bien gentil tout ça, mais comment fait on marche arrière ? Comment à partir de la transformation de Burrow-Wheeler revenons nous au texte original?
Tout d'abord, nous allons créer la première ( LC: Left Column ) et la dernière colonne (RC Right Column) de la matrice. La dernière colonne, c'est le texte transformé que nous avons en entrée. La première se calcule facilement, il suffit d'ordonner lexicographiquement les lettres de la dernière colonne.
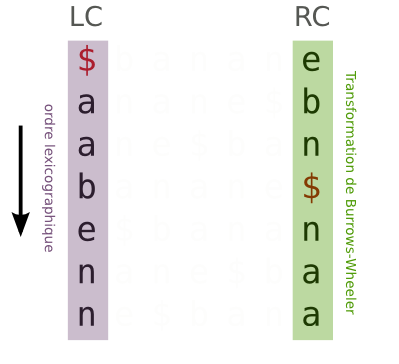
Je ne vais pas vous le détailler ici, mais sachez que le rang des lettres dans la colonne de gauche correspond au même dans la colonne de droite. C'est à dire que le premier "A" de la colonne de gauche correspond au premier "A" de la colonne de droite. De même le deuxième "N" de la colonne de gauche est le même que le deuxième "N" de la colonne de droite.
D'autre part, en se rappelant comment est construite la matrice, chaque lettre de la colonne de droite précède, dans le mot original, la lettre de la colonne de gauche.
Sachant tout cela, on va pouvoir récrire le mot original en l'écrivant de droite à gauche.
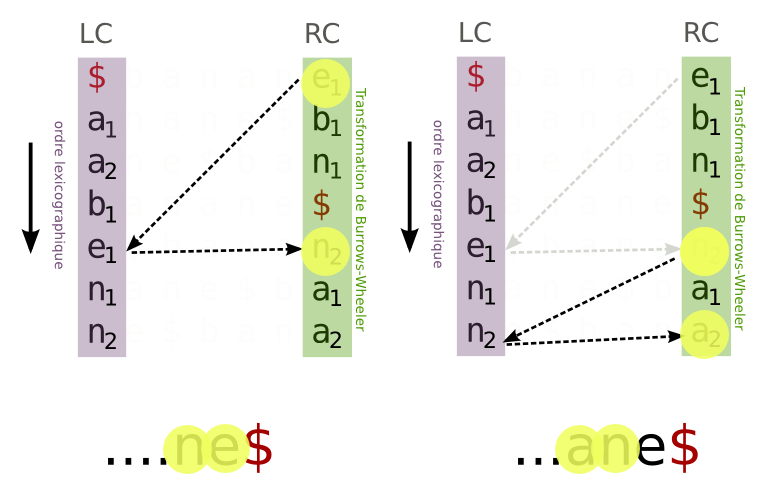
On part de la première ligne, et on lit toujours dans la colonne de droite. La première lettre correspond a "E1", c'est la dernière lettre du mot banane. On recherche ce même "E1" dans la colonne de gauche. La lettre qui précède ce E est le "N2". C'est l'avant dernière lettre du mot banane. On recherche de la même façon ce "N2" dans la colonne de gauche. La lettre qui le précède est "A2", c'est l'avant avant dernière lettre du mot banane etc....
En continuant ce processus, l'intégralité du mot qui a servi d'entrée à la transformation de Burrow-wheeler est retrouvé.
Et voici le code qui parlera plus à certain :
def rankBwt(bw):
''' Retourne les rangs '''
tots = dict()
ranks = []
for c in bw:
if c not in tots:
tots[c] = 0
ranks.append(tots[c])
tots[c] += 1
return ranks, tots
def firstCol(tots):
''' retourne la premiere colonne '''
first = {}
totc = 0
for c, count in sorted(tots.iteritems()):
first[c] = (totc, totc + count)
totc += count
return first
def reverseBwt(bw):
''' Retourne le texte original de la transformation bw '''
ranks, tots = rankBwt(bw)
first = firstCol(tots)
rowi = 0
t = "$"
while bw[rowi] != '$':
c = bw[rowi]
t = c + t
rowi = first[c][0] + ranks[rowi]
return t
Conclusion
La transformation de Burrow-Wheeler, est utilisé en compression des données, notamment dans l'algorithme de compression Bzip2. Mais une autre utilisation en bioinformatique, est la recherche de plusieurs chaînes de caractères dans une plus grande, à l'aide d'un index appelé FM-Index. L'algorithme Bowtie2 et BWA sont deux exemples d'utilisation de cette index. Ils permettent de retrouver rapidement, des séquences dans le génome humain. Nous verrons cette partie dans un prochain article !
Référence
Ce site est versionné sur GitHub. Vous pouvez corriger des erreurs en vous rendant à cette adresse
Go Top
comments powered by Disqus